


Hoje vamos falar de
treinamento de redes neurais e, para isso, eu peguei aquele ambiente que eu já
tinha instalado no Linux, que tratei no vídeo da semana passada. Trata-se,
então, de um ambiente com rede neural, Yolo, Cuda, e, agora, vamos treinar uma
rede para reconhecer o meu rosto.

Vamos, portanto, fazer uma
aplicação com YOLO, criando um modelo customizado de reconhecimento. Vamos,
portanto, tratar dos pré-requisitos preparando os dados (imagens), fazer um
arquivo próprio de configuração (cfg), além de treinar modelo customizado e
rodar um modelo treinado no YOLO.

PRÉ-REQUISITOS

Para rodar as redes neurais
profundas (DNN) é necessário o uso de
computação paralela utilizando GPU.
Por isso vamos precisar de uma
placa de vídeo potente da NVIDIA e rodar o algoritmo com o uso da API CUDA
(conjunto de instruções virtuais da
GPU).

Para rodar o algoritmo
primeiro é necessário ter instalado os seguintes pacotes:
- Drive Placa de VídeoNvidia
- CUDA
- CUDNN (Biblioteca de Deep Neural Network do CUDA)
- OpenCV


·
Computador
Configurações do Computador

SETUP DARKFLOW
Abra o terminal e digite os
seguintes comandos:

É criado o diretório “images”
para colocar as imagens de treinamento e o diretório annotations para colocar
os labels e posições do objeto a ser reconhecido na imagem.
Download pesos pré-treinados
Entre no link e baixe os pesos pré-treinados do seu interesse. Nesse projeto utilizamos o
arquivo “yolo.weights”. Coloque ele dentro do diretório “bin” do darkflow.

PREPARANDO OS DADOS
O que reconhecer?
Como vamos treinar um modelo
customizado, é necessário primeiramente ter em mente o que quer reconhecer.
Escolha um objeto ou algo do
seu interesse para reconhecer, colete arquivos de mídia para treinamento como
imagens e vídeos e coloque as imagens dentro do diretório “images” criado no
darkflow.
Se a mídia for de vídeo, tire
uma quantidade boa de screenshots do vídeo.

Banco Utilizado
Foram utilizadas 48 imagens do
meu rosto.
É importante que as imagens
sejam diferentes para assim o reconhecimento ficar com uma acurácia melhor.
Utilizar imagens:
·
Capturadas em lugares diferentes
·
Iluminação diferente
·
Perspectiva diferente
·
Diferentes lados

Assim é possível que o
algoritmo detecte todas as características do objeto para o reconhecimento.
Banco de imagens utilizado

Anotações com retângulos
É necessário sinalizar e
colocar um label no objeto que deseja reconhecer.
Foi utilizada a ferramenta labelimg.

Como utilizar labelimg
Vá em OpenDir e abra o
diretório que se encontra as imagens de treino (“darflow/images”).

Vai abrir e as imagens vão ficar
no canto inferior direito. Agora é preciso delimitar o objeto com uma RectBox,
clique em “Create\nRectBox”.

Selecione o objeto que deseja
reconhecer. Como vou reconhecer meu rosto, criei o retângulo no meu rosto:

Depois basta salvar clicando
em “Save” e salvar no diretório “annotations” criado em darkflow.
Vá em “Next Image” e repetir
esses passos em todas as imagens.

ARQUIVO DE CONFIGURAÇÃO (cfg)
É preciso fazer pequenas
alterações no arquivo de configuração (*.cfg) para ajustar ao modelo ao seu
próprio conjunto de dados. Por exemplo, o modelo CNN do YOLOv2 é treinado no
dataset do ImageNet e contém várias classes de objetos diferentes. Já aqui
nesse exemplo têm apenas um objeto (FernandoK)
No diretório “darflow/cfg”
copie o arquivo “yolo.cfg” e renomeie o arquivo para “yolo-new.cfg”.
Abra esse arquivo e é
necessário fazer algumas alterações.

Alterações do Arquivo de configuração
·
Altere as classes na camada [region] (a última
camada) para o número de classes para as quais você vai treinar. No meu caso,
as classes são definidas como 1.
·
Mude os filtros na camada [convolutional] (a
última camada convolutional) para num*(classes+5).
Como utilizado o arquivo
“yolo.weights” o num é 5 e o número de classes é 1. Então: 5*(1+5) = 30.
Portanto, os filtros são
definidos como 30.

Especificar as Classes
Altere o arquivo “labels.txt”
incluído no diretório darkflow. Apenas especifique os nomes de objetos que
deseja reconhecer.
No meu caso, removi todos o
texto e deixe apenas “FernandoK”.

OPÇÕES DO MODELO

TREINO
Para treinar basta colocar o
arquivo treino.py no diretório darkflow, abrir o terminal e rodar o comando:
Utilizando uma NVIDIA 1660
levou cerca de 4 horas para o treino com as configurações utilizadas.

treino.py
#importar rede
from darkflow.net.build import TFNet
#opções do treino
options = {"model": "cfg/yolo-new.cfg",
"load": "bin/yolo.weights",
"batch": 1,
"epoch": 100,
"gpu": 1.0,
"train": True,
"annotation": "./annotations/",
"dataset": "./images/"}
#configurando a rede com as opções
tfnet = TFNet(options)
#treino
tfnet.train()
RECONHECIMENTO EM UMA IMAGEM
Coloque a imagem que queira
reconhecer na pasta darflow/sample_img e altere o nome da imagem no arquivo
imagem.py
Para reconhecer basta colocar
o arquivo imagem.py no diretório darkflow, abrir o terminal e rodar o comando:

Reconhecer - Input Image

Reconhecer - Output Image

imagem.py / Boxing
#função para criar o retangulo
def boxing(original_img , predictions):
newImage = np.copy(original_img)
#cria um box pra cada objeto detectado
for result in predictions:
top_x = result['topleft']['x']
top_y = result['topleft']['y']
btm_x = result['bottomright']['x']
btm_y = result['bottomright']['y']
confidence = result['confidence']
label = result['label'] + " " + str(round(confidence, 3))
#se for maior que 30% mostra
if confidence > 0.3:
#desenha o retangulo
newImage = cv2.rectangle(newImage, (top_x, top_y), (btm_x, btm_y), (255,0,0), 6)
#escreve o texto
newImage = cv2.putText(newImage, label, (top_x, top_y-5), cv2.FONT_HERSHEY_COMPLEX_SMALL , 3, (0, 230, 0), 1, cv2.LINE_AA)
return newImage
imagem.py
#importar biblioteca numpy
import numpy as np
#importa biblioteca da rede
from darkflow.net.build import TFNet
#importar opencv
import cv2
#opções para carregar o modelo
options = {"model": "cfg/yolo-new.cfg",
"load": -1,
"gpu": 1.0}
#configura a rede com as opções
tfnet2 = TFNet(options)
#carrega a rede
tfnet2.load_from_ckpt()
#Le a imagem
original_img = cv2.imread("sample_img/3.jpg")
#Reconhece objetos na imagem
results = tfnet2.return_predict(original_img)
if results:
print("\nResults---------------------------------------------------")
#Para cada objeto reconhecido printa o nome e com qual confiança
for y in range(0, len(results)):
print("Label:%s\tConfidence:%f"%(results[y]['label'], results[y]['confidence']))
#mostra imagem
cv2.imshow('image',boxing(original_img, results))
cv2.waitKey(0)
cv2.destroyAllWindows()
RECONHECIMENTO POR WEBCAM
Para reconhecer basta colocar
o arquivo webcam.py no diretório darkflow, abrir o terminal e rodar o comando:

Reconhecimento Webcam 1

Reconhecimento Webcam 2
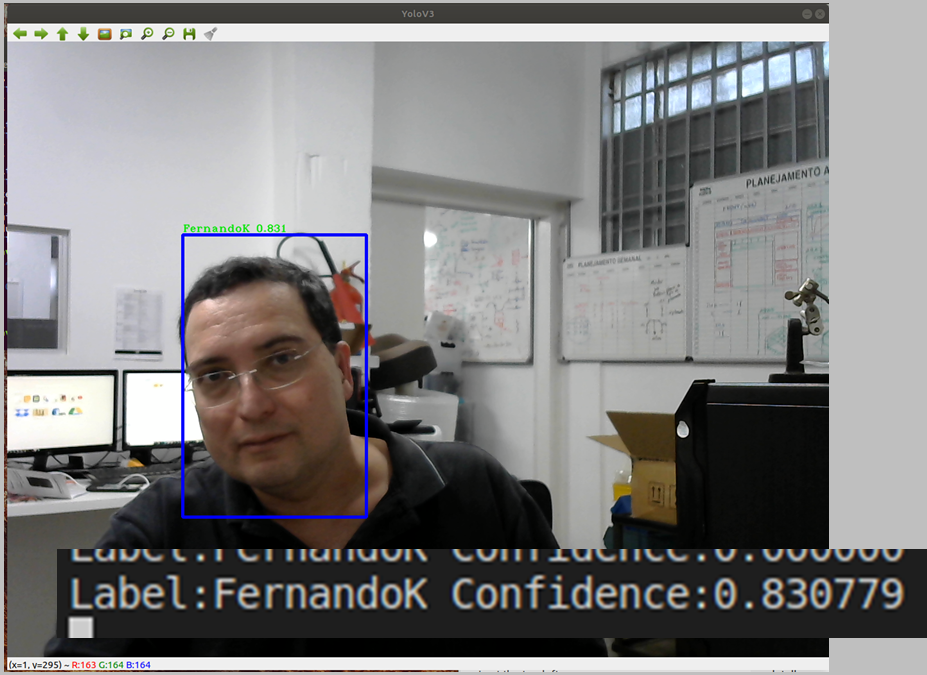
Reconhecimento Webcam 3

webcam.py
#importar biblioteca numpy
import numpy as np
#importa biblioteca da rede
from darkflow.net.build import TFNet
#importar opencv
import cv2
#opções para carregar o modelo
options = {"model": "cfg/yolo-new.cfg",
"load": -1,
"gpu": 1.0}
#configura a rede com as opções
tfnet2 = TFNet(options)
#carrega a rede
tfnet2.load_from_ckpt()
#Captura video
cam = cv2.VideoCapture(0)
#Cria janela chamada YOLO
cv2.namedWindow("Yolo")
while True:
#Lê frame
ret, frame = cam.read()
#Reconhece objetos no frame
results = tfnet2.return_predict(frame)
if results:
print("\nResults---------------------------------------------------")
for y in range(0, len(results)):
#Para cada objeto reconhecido printa o nome e com qual confiança
print("Label:%s\tConfidence:%f"%(results[y]['label'], results[y]['confidence']))
#mostra imagem
cv2.imshow('YoloV3',boxing(frame, results))
#Se não encontra frame
if not ret:
break
k = cv2.waitKey(1)
#Se Clicar no Esc fecha
if k%256 == 27:
print("Escape hit, closing...")
break
#Libera os recursos de software e hardware da câmera
cam.release()
#Destroi a janela
cv2.destroyAllWindows()








6 Comentários
Olá Fernando! Parabéns pelas abordagens de IA!!! É possível desenvolver projeto semelhante, utilizando o Nvidia Jetson Nano?
ResponderExcluirObrigado. Abraço.
Sistema da lechi segurança rodando a partir de um jetson nano.
Excluirhttps://www.facebook.com/watch/?v=485202615565154
Como eu faço a instalação do CUDA e CUDNN no ubuntu?
ResponderExcluirImagens precisa ser jpg?
ResponderExcluiro Meu está dizendo que não encontra a pasta ./ckpt/yolo-new-500.profile,
ResponderExcluiraparece quando finalizo o treinamento
Putz, aqui para mim também. :(
Excluir